

多數人透過實際聆聽音樂來了解其優美之處,但當他們被要求呈現統計數據時卻常常只秀出冷冰冰的音符,而不實際演奏這些音符所代表的音樂。
─ 漢斯・羅斯林
我們在《真確》:如何用 30 秒了解台灣發展與全球趨勢時提過,一張設計良好的資訊圖表遠比一堆冷冰冰的統計數據更能為眾人提供價值。在這篇文章裡,你將了解如何透過幾行簡單的 Python 程式碼來取得與台灣相關的 COVID-19 數據,並製作與衛福部疾管署首頁相似的趨勢圖表。讀完本文你可以發揮自己的創意生成新的資訊圖表,進一步了解 COVID-19 疫情。
這邊值得一提的是以上截圖並不反應最新疫情。事實上,圖中的實際數值也並不那麼重要。你只需稍微了解有哪些指標(確診數、送驗數等)以及兩張圖分別想要呈現的疫情趨勢即可。我們馬上就會透過 LeafLu 與眾多 PTT 鄉民辛勤為社會大眾整理的 Google 試算表來取得疾管署公布的最新疫情結果。以下就是我們即將存取的試算表:
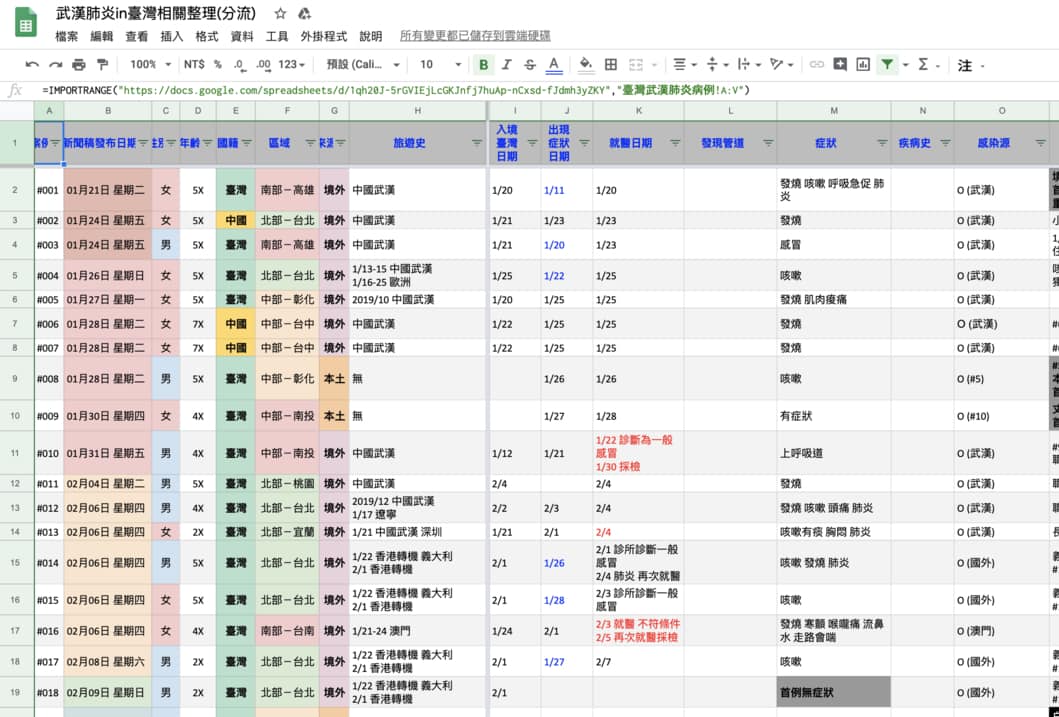
這個試算表定期更新台灣所有的確診案例以及其他相關疫情資訊,十分強大。另外注意我們即將使用的是分流版本的試算表,以盡可能減少對主要試算表的存取要求。你當然也可以自行打開該試算表並 Ctrl + C、Ctrl + V 複製自己想要的數據,但我們可以更聰明一點,用 Python 自動化這些步驟。
pandas 建立在 Python 程式語言之上,是一個快速、強大且具備彈性的資料分析與數據處理工具。pandas 也是資料科學家不可不掌握的數據處理利器之一。
整個專案我們都將使用資料科學家們已經十分熟悉的 pandas 來處理疫情相關的數據。如果這是你第一次知曉 pandas 並打算快速且有系統地學習,稍後可以參考資料科學家的 pandas 實戰手冊:掌握 40 個實用數據技巧。不過要用 pandas 存取公開的 Google 試算表十分容易。比方說我們現在想要取得台灣 COVID-19 的檢驗人數:
import pandas as pd # 用 pandas 的標準起手式
# Google 試算表的基本 url pattern
GOOGLE_SHEET_URL = "https://docs.google.com/spreadsheets/d/{}/export?gid={}&format=csv"
# 透過 `pd.read_csv` 函式直接透過 url 將 Google 試算表轉成 DataFrame 並做簡單數據前處理
columns = ['日期', '檢驗人數', '確診人數', '居檢送驗', '居檢送驗累計',
'武肺通報', '武肺通報累計', '擴大監測', '擴大監測累計']
tests = (
pd.read_csv(GOOGLE_SHEET_URL.format(
"1Kp5IC5IEI2ffaOSZY1daYoi2u50bjUHJW-IgfHoEq8o", # 分流試算表 id
1173642744 # `檢驗人數` 工作表的 gid
))
.loc[:, columns] # 這邊我們為了畫面簡潔只選出需要使用的欄位
)
# 補空值、將浮點數改為整數方便閱讀
tests.fillna(value={col: 0 for col in tests.columns[1:]}, inplace=True)
for col in tests.columns[1:]:
tests[col] = tests[col].astype(int)
# 顯示最新幾天的檢驗數據
tests.tail()
# 注意:這邊是為了教學目的特別把 import 放在這裡
import pendulum
# 給當前一天累計的確診數加上最新日期(如果還沒加的話)
# 如果你現在不了解這段程式碼也沒有關係,只要知道輸出的 DataFrame 的長相就可以了
na = (tests['日期'].isna())
prev = tests.loc[~na].tail(1)['日期'].iloc[0]
prev_dt = pendulum.date(2020, *[int(s) for s in prev.split("/")])
latest_dt = prev_dt.add(days=1)
tests.loc[na, ['日期']] = f"{latest_dt.month}/{latest_dt.day}"
# 將本來的日期字串改為更為通用的 `年年年年-月月-日日` 格式
# 很多繪圖函式庫能夠自動將這種格式的字串解析成對應的日期物件
tests['日期'] = tests['日期'].str.split('/')\
.apply(lambda x: pendulum.date(2020, int(x[0]), int(x[1])).format("YYYY-MM-DD"))
# 我們這邊用 pandas 實戰手冊提過的 df.style 來強調修改後的日期欄位
(tests.tail(5)
.style
.applymap(lambda x: 'background-color: rgb(153, 255, 51)',
subset=['日期']))
你很快就會看到以這種格式儲存日期資訊的方便之處。現在讓我們透過這個簡單表格來重現疾管署首頁展示的圖表。
讓我們再次回顧一下疾管署所公布的 COVID-19 疫情圖表:
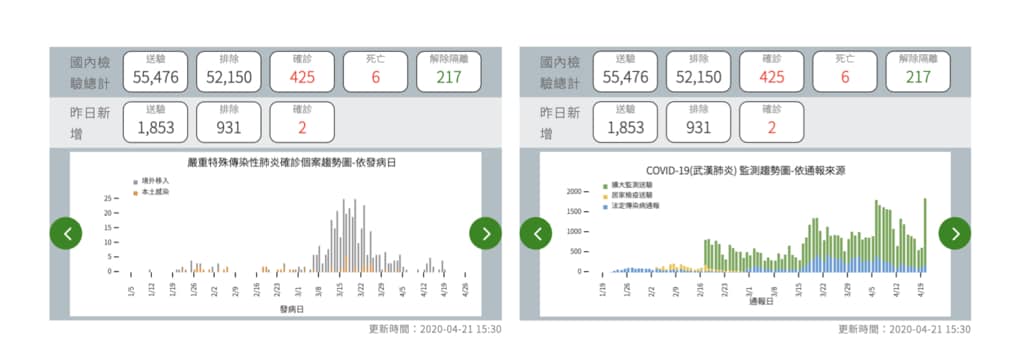
這邊我們簡單重現第一列「國內檢驗總計」裡頭的兩個指標:送驗以及確診。
pd.DataFrame({
'送驗': [tests['檢驗人數'].sum()],
'確診': [tests['確診人數'].sum()],
})
沒什麼魔法。多虧了鄉民們的努力,基本上你能輕鬆計算出跟疾管署大致相同的結果。以我們的使用案例而言(簡單資料視覺化、查看整體趨勢等),小誤差並不會造成什麼不良影響。不過如果你要非常精準的數字,我還是建議你查看疾管署首頁。這邊的重點是你現在已經有能力取得足夠精準、即時的疫情數據並進行更多疫情分析了。
我們當然也能自行算出「昨日新增」的相關數據:
yesterday_dt = pendulum.yesterday(tz="Asia/Taipei").format("YYYY-MM-DD")
tests[tests['日期'] == yesterday_dt].loc[:, ['日期', '檢驗人數', '確診人數']]\
.rename({'檢驗人數': "送驗", '確診人數': '確診'}, axis=1)
如同本文開頭所述,將疫情總結為一個統計數字固然強大,但當你想要暸解疫情趨勢時.僅僅秀出一個數字是不會有任何幫助的。這也是為何疾管署在確診人數下方還描繪了每日的確診人數變化,就是為了讓大眾能在掌握最新狀況的同時也能夠了解整體趨勢變化。
在下一節,我將展示你可以如何用 Python 來描繪相似的趨勢圖表。
依照使用情境以及當下心情(?),一般我會用不同的 Python 函式庫來視覺化手中數據,比方說大家耳熟能詳的 Matplotlib、Seaborn 或是強調互動性的 Plotly。我也曾介紹過由 Spotify 開源,跟 Altair 一樣用宣告型語法繪圖的 Chartify。但如果現在要我向你推薦一個 Python 函式庫的話,我會說:「去學學 Altair 吧!」
Altair 有幾個我認為值得特別列出來的優點:
- 宣告型語法易上手、直覺,客製化能力強
- 使用心法符合我們之前討論過的圖像分層文法
- 預設樣式優美,不像 Matplotlib 得自己修東修西
- 具備跟 R 語言的 ggplot2 一樣強大的 facet 功能
- 能輕易加入互動機制,且寫法比 Plotly 來得 Pythonic
在 COVID-19 的系列文章裡,我會展示各種你可以透過 Altair 來輕鬆繪製的美麗圖表。事不宜遲,讓我們再次將目光放到疾管署右側的監測趨勢圖上。該圖將每天的送驗次數依照通報來源分為三種類別:
- 居家檢疫送驗
- 擴大監測送驗
- 法定傳染病通報
要自己生成這個趨勢圖並不難,因為我們手上已經有各通報來源的每日送驗數目:
#collapse-hide
# 用來強調接著會使用的欄位的樣式函式,讀者不需細讀這段程式碼
def highlight_column(data, color="rgb(153, 255, 51)"):
attr = 'background-color: {}'.format(color)
return [attr for v in data]
(tests.tail().style
.apply(highlight_column,
subset=["居檢送驗", "武肺通報", "擴大監測"],
axis=1)
)
在使用 Altair 畫圖前我們得將數據轉成 tidy 格式,就跟我們之前使用 Chartify 一樣。tidy 數據具有以下 2 特性:
- 1 變數只存在 1 欄裡頭(1 variable in a column)
- 1 列代表 1 個觀測結果(1 observation in a row)
這邊我們關注的變數是一個有三種可能值的「通報來源」。一般會利用 pandas 的 melt 函式來產生 tidy 數據:
data = (
tests
.rename({ # 用跟疾管署一致的 naming convention
'擴大監測': '擴大監測送驗',
'居檢送驗': '居家檢驗送驗',
'武肺通報': '法定傳染病通報',
}, axis=1) # 這邊的關鍵是使用 `melt` 來建立 `通報來源` 變數
.melt('日期', ['擴大監測送驗', '居家檢驗送驗', '法定傳染病通報'],
var_name='通報來源', value_name="通報數")
.fillna(0)
)
data.tail()
在 data 裡頭,每一列都代表著某個通報來源在某一天的通報數。有了 tidy 格式的 DataFrame 後,要用 Altair 繪製 COVID-19 的每日監測趨勢就變得十分容易了。我們只需將數據中的變數對應到想要呈現的視覺變數上就可以了:
import altair as alt # 使用 altair 的標準起手式
_ = alt.renderers.set_embed_options(actions=False) # 隱藏下載圖片的按鈕以節省空間
alt.Chart(data).mark_bar( # 繪製柱狀圖
# 將數據變數編碼(encode)到視覺變數上
).encode(
x="日期:T", # 將日期對應到 x 軸上
y="通報數:Q", # 將通報數對應到 y 軸上
color="通報來源:N" # 將通報來源對應到顏色
# 設置整個圖的屬性
).properties(
width=700 # 圖表寬度
)
沒錯,我們剛剛用 Altair 生成了第一個 COVID-19 圖表!透過上圖我們也能清楚地觀察到在今年 2 月中旬後擴大監測的通報數明顯上升,而法定傳染病通報則在 3 月中旬後達到巔峰。這是我們無法從試算表一眼看出的趨勢。
就算這是你第一次知曉 Altair,我相信搭配註解你會同意其使用方式十分直覺;忽略註解你也可以發現能用非常簡潔的宣告型語法(declarative syntax)來繪製出高品質的圖表:
# 去除註解的最簡 Altair 繪圖呼叫方式
alt.Chart(data).mark_bar().encode(
x="日期:T"
y="通報數:Q"
color="通報來源:N"
)
沒錯,用 Altair 做資料視覺化就是那麼地樸實無華,簡單到可能有些資料科學家都不想跟你分享這個強大工具,以免失去工作(笑
我們之前在淺談資料視覺化以及 ggplot2 實踐就已經說過:
資料視覺化是將數據映射到視覺變數,進而有效且有意義地呈現數據的真實面貌。
透過 Altair 直覺的宣告型語法,我們可以專心思考如何用最有效的視覺變數來呈現數據,而不是將寶貴的精力花在微調樣式上面。有趣的是,Altair 的核心思想跟我們之前聊過用 SQL 抽取數據的精神是完全一致的:
- Altair: 告訴程式你要畫什麼圖表,而不是如何畫
- SQL:告訴程式你要拿什麼數據,而不是如何拿
兩者都可以讓我們專注在最重要的目的(what),而不是手法(how)。
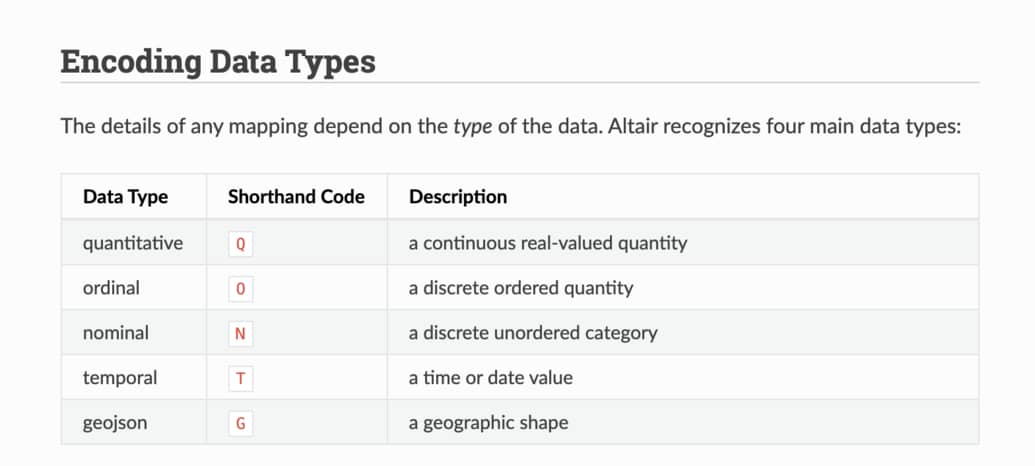
另外注意我們用 日期:T 來告訴 Altair 日期 這欄位的數據類型為時間(Time),且因為我們已經事先把代表日期的字串轉成通用的 YYYY-MM-DD 格式, Altair 在繪圖時能夠自動解析日期並呈現如上圖 x 軸的美麗結果(你可以拉回去看看)。其他數據類型都很直覺,這邊就不再一一贅述。
你已經看到要用 Altair 繪製基本的圖表有多麽地簡單。但 Altair 更厲害的地方在於你可以輕易地客製化原來的圖表,比方說改變 x 軸渲染的日期格式、添增提示框等新的互動效果:
chart_title = "COVID-19(武漢肺炎)監測趨勢圖 - 依通報來源"
alt.Chart(data, title=chart_title).mark_bar()\
.encode(
x=alt.X('日期:T', title="通報日", axis=alt.Axis(
grid=False, # 去除縱軸的格線
format="%m/%d", # 自定義日期格式
)),
y="通報數:Q",
color='通報來源:O', # 將通報來源視為有序類別
tooltip=['日期:T', '通報來源', '通報數'] # 加上提示框
).properties(
width=700
)
至此,我們完整地重現了疾管署首頁所呈現的 COVID-19 監測趨勢圖。透過添加 tooltip 參數,你現在還可以將滑鼠移動至圖上查看各個通報來源的實際數值;這次我們則將通報來源視為有序變數(ordinal variable),讓 Altair 自動套用相同色系的漸層效果,強調檢測能量分別在 2 月以及 3 月中旬有強化的趨勢。
進度 50 %。接著讓我們重現疾管署公布的境內外確診人數趨勢:
左圖依照發病日期展示了台灣每天境內外的確診人數趨勢。要重現這張趨勢圖,我們得先想辦法拿到相對應的境內外確診數據。這次我們將存取公開試算表中的臺灣武漢肺炎病例工作表:
cases = (
pd.read_csv(GOOGLE_SHEET_URL.format(
"1Kp5IC5IEI2ffaOSZY1daYoi2u50bjUHJW-IgfHoEq8o",
0 # `臺灣武漢肺炎病例` 工作表的 gid
))
.loc[:, ['出現症狀日期', '案例', '來源', '性別', '年齡']]
)
# 這邊忽略沒有記載出現症狀日期的案例
cases = cases.loc[~cases['出現症狀日期'].isna()]
cases = cases.loc[cases['出現症狀日期'].apply(lambda x: not 'x' in x)]
# 處理時間欄位的字串讓 Altair 等等可以正確解析日期
cases['出現症狀日期'] = cases['出現症狀日期']\
.apply(lambda x: '-'.join(['2020', *x.split("/")]))
cases.tail()
很明顯地,cases 裡的每一列都代表著一個特定的台灣確診案例。而因為我們想要了解的是每一天每個通報來源的案例總數,還得使用 pandas 的 groupby 函式將 cases 依據出現症狀日期 & 來源分組並分別加總案例數:
data = (
cases
.groupby(['出現症狀日期', '來源'])['案例']
.count()
.reset_index()
)
data.tail()
就跟前面通報來源的例子相同,現在 data 已經是我們想要的 tidy 格式,因此可以馬上使用 Altair 描繪趨勢圖:
title = "嚴重特殊性傳染性肺炎確診個案趨勢圖 - 依發病日"
alt.Chart(data, title=title).mark_bar()\
.encode(
x=alt.X('出現症狀日期:T', title="發病日", axis=alt.Axis(
grid=False,
format="%m/%d")),
y='案例:Q',
color='來源:N',
tooltip=['出現症狀日期:T', '來源', '案例']
).properties(
width=700
)
畫出圖後境內外的確診人數趨勢一目了然。儘管今年 3 月起境外確診案例突增,本土感染的案例比例仍舊很低,表示台灣還沒有大規模社區傳播的現象存在。
另外從發病日來看,今年 3 月中旬的爆發已漸平緩。值得一提的是疾管署並未將 4 月中旬海軍敦睦艦隊官兵的感染事件列在境內或境外,而是另開分類。因此疾管署首頁上的境內外趨勢圖是沒有顯示敦睦類別的。(國內檢驗項目的確診數則有反應上去)
好啦!至此我們已經將疾管署網站上跟台灣相關的 COVID-19 疫情圖表完整地重現出來了。現在讓我們做點總結。
要讓公開數據發揮最大價值,我們得讓每位公民都能輕鬆存取並理解這些數據。
我想你現在已經具備能夠探索台灣 COVID-19 疫情數據的基本能力了。我也相信透過讓更多人參與並了解疫情能對我們的社會帶來一些正面的影響。你現在有幾件事情可以做:
- 查看廣大鄉民整理的台灣疫情 Google 試算表以深入了解疫情
- 回到文章開頭或利用左側導覽點擊 Colab 連結,抓取感興趣的數據分析
- 分享本文以讓更多人能夠參與研究台灣新冠疫情並最大化公開數據價值
另外如果你擔心自己對新型冠狀病毒或是傳染病的科普知識不足,我強力推薦先花 1 小時在 hahow 好學校平台上與陳建仁副總統學習防疫的基本知識:
好啦,本章節就到此告一段落!
我們在下一章會利用此章學到的數據處理技巧進一步對台灣 COVID-19 疫情做些新的視覺化與簡單分析。在那之前別忘了隨時做好自主健康管理,有任何回饋、新的視覺化圖表的建議也請讓我知道!我們下次見:)
跟資料科學相關的最新文章直接送到家。 只要加入訂閱名單,當新文章出爐時, 你將能馬上收到通知